Dawid-Skene 算法
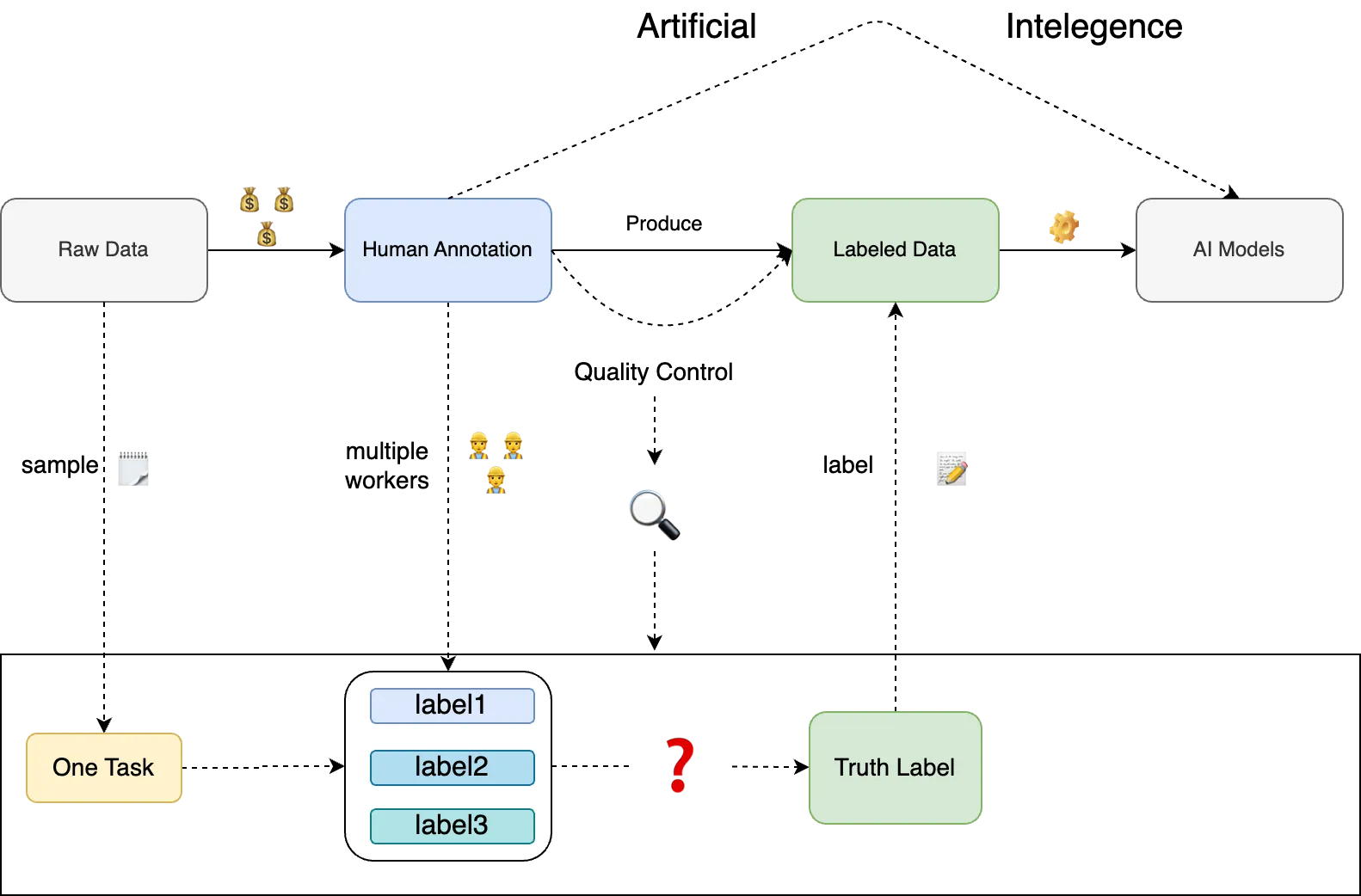
Lilian 在Thinking about High-Quality Human Data | Lil’Log 对数据标注的质量进行了一些很有远见的讨论。 这里我们主要对标签聚合算法 (真值推断) Dawid-Skene 算法进行一些较为深入讨论。
所谓标签聚合算法,是指从多个标注者的标注结果中推断出最可靠的标签。
简介
Dawid-Skene 算法最早是应用于临床医学相关的领域, 用于聚合多个临床专家对同一个病人的的判断结果。 后来被广泛应用于数据标注领域,用于聚合多个标注结果得到最可靠的标签。
算法原理
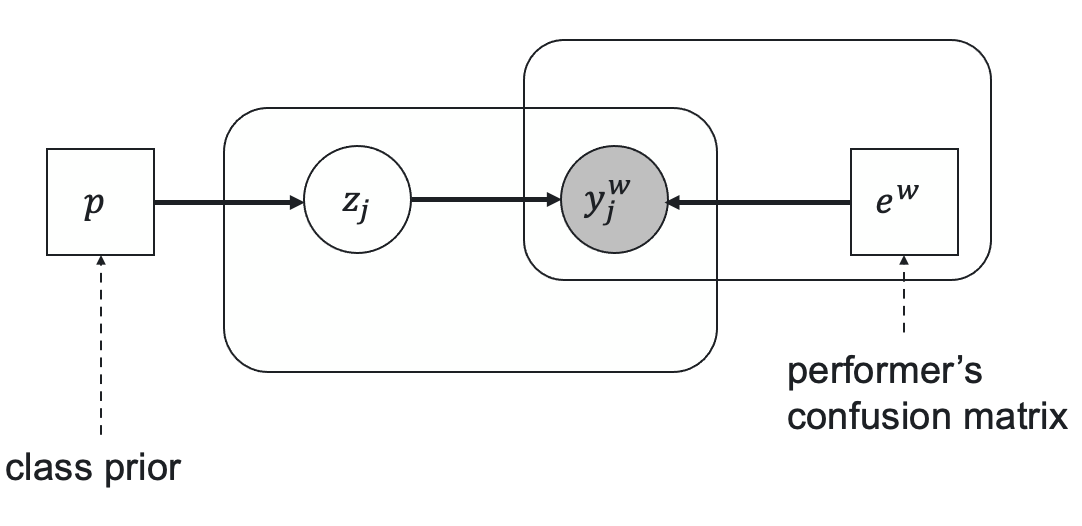 Image source: Crowd-Kit
Image source: Crowd-Kit
DS 算法是一种基于 EM 算法的标签聚合算法,我们先简要介绍 EM 算法的原理,然后再介绍 DS 算法的细节。
EM 算法推导
The Expectation Maximization Algorithm: A short tutorial 给出了一个极为详细的 EM 算法推导。这里我们就不再进行赘述。
Dawid-Skene 算法推导
Maximum likelihood estimation of observer error-rates using the EM algorithm 是 DS 算法的原始论文,给出了 DS 算法的推导。
论文本身的推导过程还算比较完善的,不过省略了较为关键的极大似然估计的推导过程,也就是通过 式 2.2:
推导出式 2.3:
和式 2.4:
所谓极大似然估计,就是先定义一个似然函数,然后通过求解的极值来求解参数, 这里求解的关键其实是通过 Lagrange 乘子法 (Lagrange multiplier) 来求解。 因为要求解的参数 和 都是概率,所以需要满足概率的约束条件, 我们用 Lagrange 乘子法来满足这个约束条件。 这里我们主要介绍 的推导过程, 的推导过程类似。
因为这里的的形式存在多个乘积,所以我们可以通过对数似然函数来简化计算。
作为概率的估计,的约束条件是:
综合以上条件,我们可以得到 Lagrange 函数:
通过对 求偏导,我们可以得到:
化简后得到:
将上式置为 0,我们可以得到:
调整一下顺序,将 隔离出来,我们可以得到:
利用约束条件来消除 以求解 ,这里通过两边同时按照 求和:
根据上述两式,我们可以得到最终的 的极大似然估计,也就是式 2.3:
至此,我们完成了 的推导, 的推导过程类似,这里不再赘述。
工程实现
以 crowd-kit 的实现代码为例。 先简要介绍 DS 算法核心的实现,然后重点介绍两个算法优化点的具体实现。
核心算法实现
class DawidSkene(BaseClassificationAggregator): # 省略部分代码 def fit( self, data: pd.DataFrame, true_labels: Optional["pd.Series[Any]"] = None, initial_error: Optional[pd.DataFrame] = None, ) -> "DawidSkene": # 省略部分代码 # Initialization probas = MajorityVote().fit_predict_proba(data) # (1) # correct the probas by true_labels if true_labels is not None: probas = self._correct_probas_with_golden(probas, true_labels) priors = probas.mean() # (2) errors = self._m_step(data, probas, initial_error, self.initial_error_strategy) # (3) loss = -np.inf self.loss_history_ = []
# Updating proba and errors n_iter times for _ in range(self.n_iter): probas = self._e_step(data, priors, errors) # (4) # correct the probas by true_labels if true_labels is not None: probas = self._correct_probas_with_golden(probas, true_labels) priors = probas.mean() # (5) errors = self._m_step(data, probas) # (6) new_loss = self._evidence_lower_bound(data, probas, priors, errors) / len( data ) self.loss_history_.append(new_loss)
if new_loss - loss < self.tol: break loss = new_loss # 省略部分代码MajorityVote是一个简单的多数投票算法,用于初始化标签的概率分布。priors是标签的先验概率。errors是 worker 标注的 confusion matrix。- EM 算法的 E 步:根据标注数据
data,标签的先验分布prioir和 worker 的混淆矩阵errors来更新标签的概率分布。 - 更新标签的先验概率。
- EM 算法的 M 步:根据标注数据
data和标签的概率分布probas来更新 worker 的混淆矩阵errors。
算法优化
这里做的优化主要有两处,分别对应 DS 算法中两个缺失的参数:
标签的先验分布priors和标注人员的混淆矩阵errors。
金标题修正标签先验分布
那么如果在数据集中有一些题目的真值标签 (即为金标题),我们如何利用上这部分信息让推断更加准确呢?
通过上面的代码可以看到,在没有真值标签的情况下,priors的初始值是通过多数投票算法得到的。
这里我们可以通过这些真值标签来修正priors。
Note (PR 链接)
class DawidSkene(BaseClassificationAggregator): # 省略部分代码 def fit( self, data: pd.DataFrame, true_labels: Optional["pd.Series[Any]"] = None, initial_error: Optional[pd.DataFrame] = None, ) -> "DawidSkene": # 省略部分代码 # Initialization probas = MajorityVote().fit_predict_proba(data) # correct the probas by true_labels # (1) if true_labels is not None: probas = self._correct_probas_with_golden(probas, true_labels) priors = probas.mean() errors = self._m_step(data, probas, initial_error, self.initial_error_strategy) # (3) loss = -np.inf self.loss_history_ = []
# Updating proba and errors n_iter times for _ in range(self.n_iter): probas = self._e_step(data, priors, errors) # correct the probas by true_labels # (2) if true_labels is not None: probas = self._correct_probas_with_golden(probas, true_labels) priors = probas.mean() # 省略部分代码self._correct_probas_with_golden是一个修正标签概率分布的函数,用于根据金标题真值标签修正标签的概率分布。这里是修正初始化的标签概率分布。- 在每次迭代中,都会根据金标题真值标签修正标签的概率分布。
能力画像修正混淆矩阵
在工业界的标注平台中,会对平台内的 worker 构建详细的用户画像用于刻画 worker 的能力。 比如我们可以通过用户历史的做题记录来构建 worker 的历史混淆矩阵。
那么我们如何利用这些历史数据来让推断更加准确呢?
通过上面的代码可以看到,在没有历史混淆矩阵的情况下,errors的初始值是将多数投票的结果作为真值算出来的。
这里我们可以通过这些历史混淆矩阵来修正errors。
Note (PR 链接)
class DawidSkene(BaseClassificationAggregator): # 省略部分代码 initial_error_strategy: Optional[Literal["assign", "addition"]] = attr.ib(default=None) # (1) # 省略部分代码 def fit( self, data: pd.DataFrame, true_labels: Optional["pd.Series[Any]"] = None, initial_error: Optional[pd.DataFrame] = None, # (2) ) -> "DawidSkene": # 省略部分代码 # Initialization probas = MajorityVote().fit_predict_proba(data) # correct the probas by true_labels # (1) if true_labels is not None: probas = self._correct_probas_with_golden(probas, true_labels) priors = probas.mean() errors = self._m_step(data, probas, initial_error, self.initial_error_strategy) # (3) loss = -np.inf self.loss_history_ = [] # 省略部分代码initial_error_strategy是一个初始化 worker 混淆矩阵的策略,可以是assign或者addition。initial_error是 worker 混淆矩阵的初始值,可以是历史混淆矩阵。- 仅仅在初始化 worker 混淆矩阵时,才会使用
initial_error。
通过上面的实现可以到历史混淆矩阵仅仅影响 worker 混淆矩阵的初始化,而不会影响后续的迭代更新。
算法的逻辑是在_m_step内部通过一行的函数调用实现:
Tip (保持核心代码的整洁)
这里通过函数调用的方式,使得核心代码的逻辑更加清晰 (保证可读性),也方便后续的维护和扩展。
class DawidSkene(BaseClassificationAggregator): # 省略部分代码 @staticmethod def _m_step( data: pd.DataFrame, probas: pd.DataFrame, initial_error: Optional[pd.DataFrame] = None, initial_error_strategy: Optional[Literal["assign", "addition"]] = None, ) -> pd.DataFrame: """Performs M-step of the Dawid-Skene algorithm.
Estimates the workers' error probability matrix using the specified workers' responses and the true task label probabilities. """ joined = data.join(probas, on="task") joined.drop(columns=["task"], inplace=True) errors = joined.groupby(["worker", "label"], sort=False).sum() # Apply the initial error matrix errors = initial_error_apply(errors, initial_error, initial_error_strategy) # Normalize the error matrix errors.clip(lower=_EPS, inplace=True) errors /= errors.groupby("worker", sort=False).sum()
return errors简单来说,我们通过上游的两个参数initial_error和initial_error_strategy,
在initial_error_apply函数来修正 worker 混淆矩阵的初始化。
从下面的代码可以看到,这种设计方式可以使得initial_error_apply函数是一个纯函数,不会对外部的状态产生影响。
def initial_error_apply( errors: pd.DataFrame, initial_error: Optional[pd.DataFrame], initial_error_strategy: Optional[Literal["assign", "addition"]],) -> pd.DataFrame: if initial_error_strategy is None or initial_error is None: return errors # check the index names of initial_error if initial_error.index.names != errors.index.names: # (1) raise ValueError( f"The index of initial_error must be: {errors.index.names}," f"but got: {initial_error.index.names}" ) if initial_error_strategy == "assign": # check the completeness of initial_error: all the workers in data should be in initial_error mask = errors.index.isin(initial_error.index) if not mask.all(): # (2) not_found_workers = errors.index[~mask].get_level_values("worker").unique() raise ValueError( f"All the workers in data should be in initial_error: " f"Can not find {len(not_found_workers)} workers' error matrix in initial_error" ) # if the values in initial_error are probability, check the sum of each worker's error matrix if (initial_error <= 1.0).all().all() and not np.allclose( initial_error.groupby("worker", sort=False).sum(), 1.0 ): # (3) raise ValueError( "The sum of each worker's error matrix in initial_error should be 1.0" ) errors = initial_error elif initial_error_strategy == "addition": # (4) errors = errors.add(initial_error, axis="index", fill_value=0.0) else: raise ValueError( f"Invalid initial_error_strategy: {initial_error_strategy}," f"should be 'assign' or 'addition'" ) return errors- 保证
initial_error的 index 和errors的 index 一致,方便后续的计算。 - 赋值策略下,因为是完全替换掉原有的 worker 混淆矩阵,所以需要保证
initial_error中包含了所有的 worker 混淆矩阵。 - 赋值策略下,是允许混淆矩阵是 count 或者 probability 的。如果检查到传入的混淆矩阵是 probability,需要保证混淆矩阵的合法性。
- 加法策略下,是将传入的混淆矩阵加到原有的混淆矩阵上。注意,这里需要保证传入的混淆矩阵的值为 count 而不是 probability (这点在文档 做了特别说明)。